

RDS
AWS에서는 데이터베이스와 연관된 많은 서비스들을 Cloud 형태로 제공하고 있다.
그중에서 RDS는 AWS에서 제공하는 관계형 데이터베이스 서비스(Relational Ratabase Service)이다.
기존 On-Premise 환경에서 우리가 많이 사용하던 기존 관계형 데이터베이스 엔진을 지원하고 있으며,
현재 작성일 기준 RDS에서는 Oracle, SQL Server, MySQL, PostgreSQL, DB2 엔진을 지원하고 있다.
그럼 AWS에서 관계형 데이터베이스 서비스인 RDS는 On-Premise 환경에서 사용했을 때와 어떤 차이가 있는지,
또 어떤 기능들이 있는지 한번 그 특징들에 대해 간략하게 살펴보도록 하자.
1. On-Premise (기존) vs AWS (Cloud)
먼저, 기존에 우리가 이용했던 On-Premise 환경, 즉 기업에서 자체적으로 데이터베이스를 설치하고 운영했을 때와 AWS Cloud 환경에서는 무엇이 다른지 알아보자.
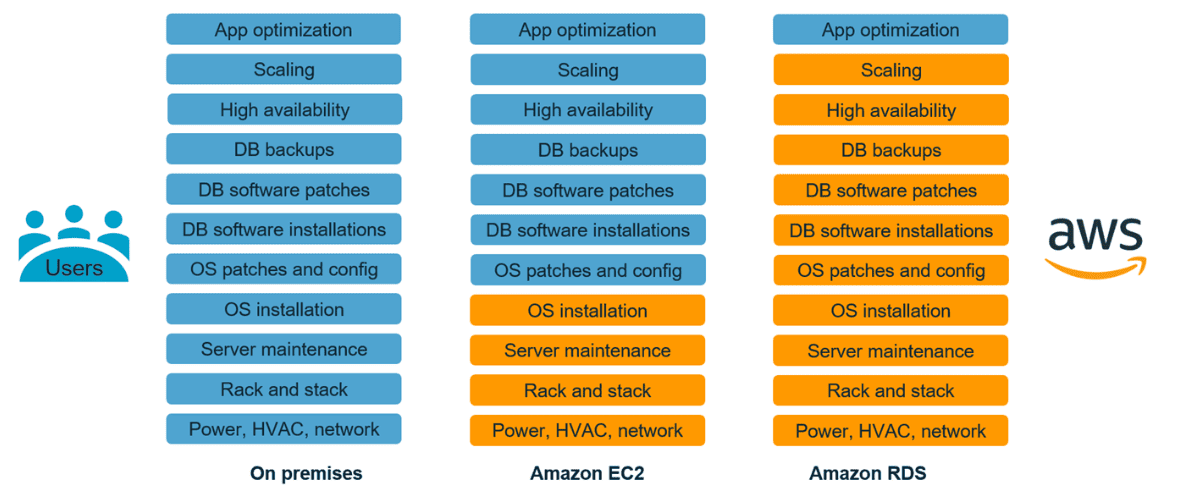
On-Premise 환경에서 DB 운영할 때를 보면 DB뿐만이 아니라 OS관리부터 시작해서 네트워크, 하드웨어, HA(DR) 구성까지 굉장히 많은 시간과 공을 들여야 했고 뿐만 아니라 규모가 큰 곳은 담당자가 모두 따로 있기 때문에 인건비나 유지 관리비가 만만치 않았다.
반면에 AWS에서 DB를 운영하는 방식은 크게 2가지 방식으로 나눌 수 있는데, AWS에서 제공하는 컴퓨팅 서비스인 EC2에 직접 설치하여 운영하는 방식과 AWS의 관리형 서비스인 RDS를 사용하는 방식이다.
On-Premise 환경에서는 앞서 말했다시피 OS, Network, Hardware, Database, Application 등 모든 계층을 기업(고객)이 모두 직접 관리해야 했다. 반면 EC2 설치형으로 DB를 운영할 때에는 DB와 애플리케이션은 기존 방식대로 운영을 하지만 OS 설치부터 시작해서 서버 운영 및 관리, 네트워크 구성 관리, 하드웨어 등 그 아래의 계층들은 AWS에서 대신 관리해 주며 안정성을 보장해 준다.
따라서 기업(고객) 입장에서는 AWS에서 OS 아래의 계층들은 대신 관리해 주니 DB와 어플리케이션에 좀 더 집중할 수 있으며 관리측면에서 부담이 줄어든다고 할 수 있다.
(사실상 DBA 입장에서 On-Premise와 EC2 설치형으로 DB를 운영할 때에는 별반 차이가 없다.)
그러면 오늘의 주제인 관리형 서비스인 RDS를 사용할 땐 어떨까?

OS와 Network, Hardware뿐 아니라 HA구성, DB 패치 등 상당 부분을 AWS에서 관리해 주기 때문에 기업(고객)은 Application과 서비스 사용자에게 집중할 수 있는 모델이 형성되고, On-Premise와 비교해 보면 상당계층에 대해서 관리주체가 AWS가 되기 때문에 부담이 현저히 줄어든다 할 수 있다.
실제로 RDS를 사용해 보면 On-Premise 환경에 비해 관리 영역이 줄어든 것은 사실이다. 또 HA구성, DB 패치, 백업구성 등 구현하기 위해 많은 시간과 기술이 필요했지만 RDS에서는 보다 효율적이고 쉽게 환경을 구축할 수 있다.
하지만 RDS를 사용한다고 하더라도 DBA의 역할은 여전히 필요하다. RDS의 내부엔진은 기존 Database Engine과 같으며 DB 최적화, 보안, 성능 튜닝, 모니터링 등의 역할이 여전히 필요하며 RDS의 내부 기능과 특징들을 적절히 이해하여 서비스에 맞게 설계하고 구성할 수 있어야 한다.
2. 운영 편의성
RDS를 운영해 보면서 가장 편했던 점은 AWS Console 창에서 RDS에 대한 전반적인 작업이 마우스 클릭으로 굉장히 쉽게 진행 가능하고 모니터링 또한 매우 용이하다는 점이다.
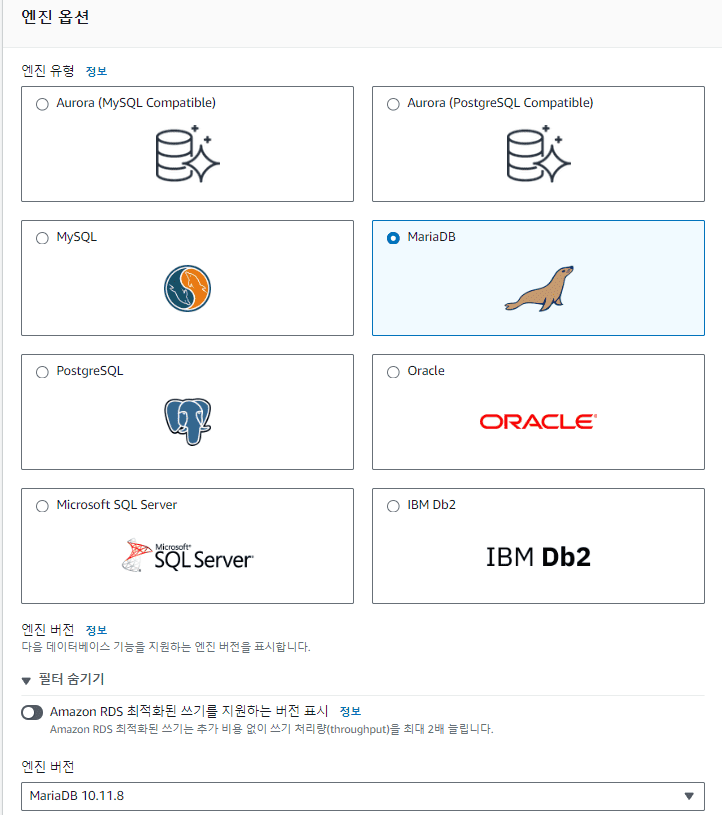
RDS는 현재 상용 DBMS로 Oracle, SQL Server 그리고 최근에 Release 된 IBM DB2엔진까지 지원하고 있으며, 오픈소스 DBMS로는 MySQL, PostgreSQL, MariaDB 등 DB 시장의 전반적인 점유율을 차지하고 있는 대부분의 엔진을 지원한다.
기존 On-Premise에서 데이터베이스를 설치하고 운영하기 위해서는 복잡한 설정과 구성, 보안, 호환성 등 그 설치과정이 복잡하고 전문인력이 필요했다.
하지만 RDS에서는 생성부터 시작하여 네트워크, HA구성, 백업 관리 등 DB에 대한 전반적인 설정들을 단 몇 분 만에 AWS Console을 통해 사용자가 마우스 클릭 몇 번으로도 구성이 가능하다.
이러한 전반적인 DB관련 설정들은 생성할 때뿐만 아니라 운영 중에도 변경이 가능하다.
(단, 일부 작업은 DB Downtime이 발생한다.)
Database Patch 작업도 설정에 따라 자동으로 지원하며 AWS Console에서 수동으로도 작업이 가능하다.
(운영 Database의 경우 자동 패치는 권장하지 않는다.)
또한 RDS에서는 DNS 기반의 Endpoint 주소로 통신하고 있다. 물론 RDS도 내부 ip가 따로 존재하긴 하지만 예기치 않은 재기동이나 Failover 등 내부 ip는 자동으로 변경될 수 있기 때문에 ip주소 대신 Endpoint를 사용하여 RDS에 직접 접근하며 이러한 Endpoint 주소는 DB ID를 변경하지 않는 이상 바뀌지 않는다.
2.1 모니터링
RDS의 모니터링은 대표적으로 AWS의 모니터링 서비스인 Cloud Watch를 마찬가지로 사용 가능하며 성능 개선 도우미라고 불리는 Performance Insight 사용이 가능하다.
Cloud Watch는 RDS의 CPU / Memory / Disk IO / Storage 등 기본적인 지표부터 Alert / Error / Slow Log 등 기존 DBMS의 로그 파일 또한 RDS 설정을 통해 모니터링이 가능하다.
또한 Cloud Watch의 다양한 RDS 지표들을 이용하여 사용자가 대시보드를 만들어 편리한 모니터링을 할 수 있다.
RDS Enhanced 모니터링은 상세 지표로 RDS에 대한 OS 지표까지 수집할 수 있다.
Performance Insight는 시간대별 DB의 부하를 좀 더 자세히 확인할 수 있는데, Top Query뿐 아니라 관련 DB Wait Event까지 모니터링이 가능하다. 그리고 DB 종류에 따라 Top Query에 대한 실행계획이라던지 상세 지표도 확인 가능하기 때문에 운영 관점에서는 매우 중요한 솔루션이다.
이밖에도 3rd party 솔루션 또한 연동되면 사용 가능하다.
3. 가용성 및 내구성
3.1 Multi-AZ
RDS에서 가용성을 보장해 줄 수 있는 기술로 Multi-AZ 기능이 있다.
기존 On-Premise 환경으로 생각하면 HA(High Availability), DR(Disaster Recovery)의 구성을 대신한다.
기업의 중요한 데이터를 보관 중인 데이터베이스에서 HA와 DR구성은 운영 데이터베이스의 핵심 전략이며 아무리 최적화가 잘되어 있고 성능이 좋은 데이터베이스라고 하더라도 내부 요인으로 인해 장애가 발생한다던지 재해로 인해 데이터센터가 날아간다면 아무 의미 없을 것이다.
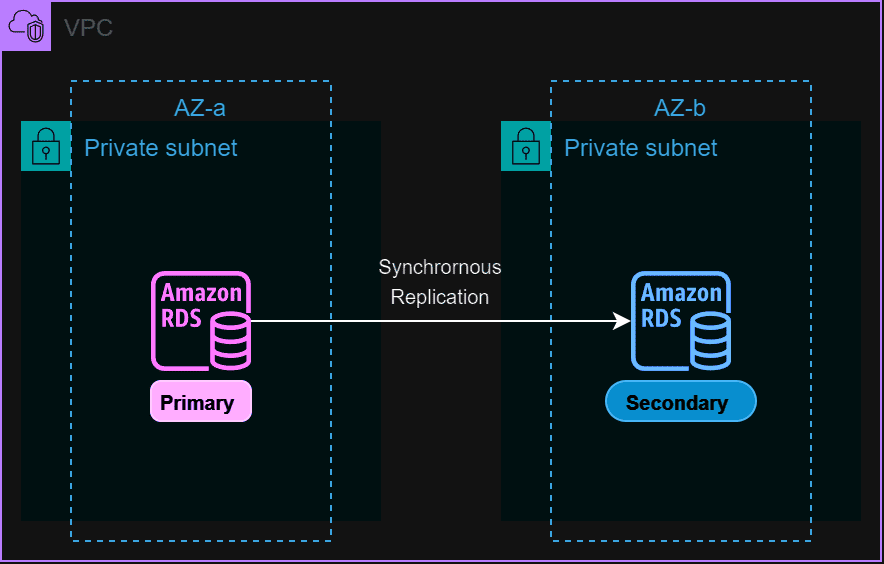
RDS의 Multi-AZ 기능은 AWS Cloud 내 서로 다른 가용영역(AZ), 즉 운영 중인 Primary DB와 물리적으로 떨어져 있는 데이터센터에 Standby DB가 구성되며 동기식 복제로 높은 가용성을 보장한다.

Standby DB는 예기치 못한 장애상황 발생 시, 운영 중인 Primary DB(원본)과 자동으로 Failover가 이루어지며 통상적으로 1~2분 내외로 완료된다. 이때 기존 RDS의 Endpoint는 그대로 유지되기 때문에 Application/Was 에서는 변경 없이 기존 연결방식으로 사용 가능하다.
다만 Multi-AZ로 새로 구성된 Standby DB는 평상시 사용자가 접근 불가능하며 오로지 장애상황을 대비하기 위한 RDS의 HA, DR 기능이다. 때문에 운영 데이터베이스의 경우 해당 기능은 필수라 할 수 있지만 비용은 2배가 된다는 점을 염려해 두자.
3.2 Read Replica
RDS의 Read Replica (읽기 전용 복제본)은 성능과 내구성을 보장한다.
비동기식 복제로 데이터베이스의 읽기 작업을 분담하여 워크로드 부하를 완하 시킬 수 있으며 트래픽 분배뿐 아니라 상황에 따라 Master로 승격시킬 수 있다.
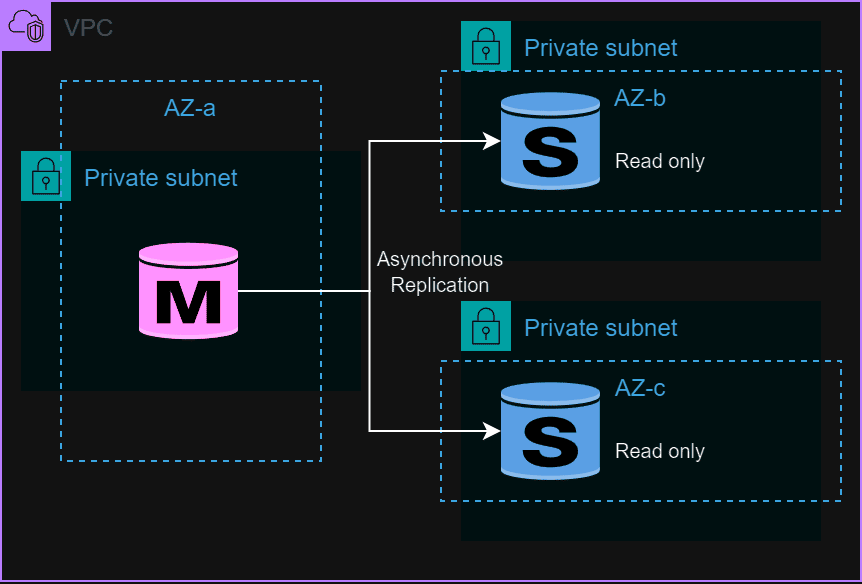
기존 DBMS 별로 사용하던 Replication 기능으로 적용되어 구성되기 때문에 Multi-AZ와 달리 DBMS 엔진별로 약간의 제약사항이 있을 수 있으며 비동기식 복제로 높은 내구성을 보장한다. 마찬가지로 AWS Console상에서 마우스 클릭 몇 번으로 구성이 가능하다.
또한 하나의 독립적인 RDS 인스턴스가 생성되는 방식이기 때문에 RDS Endpoint는 별도로 존재하며 Master와는 다른 설정으로 세팅이 가능하다. Replica의 기본 설정은 Read_only이며 수정이 가능하지만, DBMS 내부 Replication 기능으로 이루어져 있기 때문에 권장하지는 않는다.
이러한 Read Replica 기능은 다른 가용 영역(AZ) 혹은 다른 Region에도 생성이 가능하다는 장점이 있으며 목적에 따라 읽기 트래픽 분배, 장애 대응, 내부 사용 등 다양한 목적으로 사용할 수 있지만 Multi-AZ와 달리 장애 감지 시 자동 Failover 등의 기능은 지원하지 않으며 Master로 승격 시 수동으로 진행해야 한다.
(승격 시에는 Replication 구조에서 Master가 되는 구조가 아닌 기존 복제 구성에서 벗어나 하나의 인스턴스로 승격된다.)
또한 Endpoint를 별도로 가지고 있기 때문에 실질적인 읽기 트래픽 분배를 위해서는 Application/Was 에서 해당 Read Replica의 Endpoint 별도 지정이 필요하다.
RDS의 Read Replica는 RDS의 HA와 DR 기능이 아닌 워크로드 분배로 Scale Out 기능이 목적이다.
3.3 Multi-AZ VS Read Replica
| Multi-AZ | Read Replica | |
| 목적 | 가용성 보장 (HA, DR) | 성능 및 내구성 (Scale Out) |
| 복제 | 동기식 복제 (전용선 사용) | 비동기식 복제 (DBMS Replication) |
| 기능 | 장애 감지 및 자동 Failover (1~2분) | 읽기 워크로드 분배 목적에 따른 사용 가능 |
| 특징 | 사용자 접근 불가능 Failover 시 기존 RDS Endpoint 유지 물리적으로 분리된 인프라 |
사용자 접근 가능 독립적인 DB Instance 개별 RDS Endpoint 사용 다른 가용영역 및 다른 Region 생성 가능 |
Multi-AZ는 RDS의 가용성을, Read Replica는 RDS의 워크로드 분배를 목적으로 설계된 기능임을 명심하자.
4. Snapshot (Backup)
백업은 안전하게 데이터베이스를 운영하기 위해 매우 중요한 요소 중 하나이다.
예기치 못한 상황을 대비하여 수용 가능한 RPO와 RTO를 생각하고 백업 전략을 세워야 하며 그에 따른 복잡한 설정이 필요하다.
RDS에서는 인스턴스 레벨의 자체 백업을 지원하고 있으며 Snapshot(스냅샷)으로 이를 보장하고 있다.
마찬가지로 AWS Console에서 사용자가 쉽게 구성 가능하며 수동 / Autobackup 모두 사용 가능하다.
RDS Snapshot은 증분 백업 방식으로 초기 백업 시에는 Full Backup으로 진행되며 이후 스냅샷에는 데이터 변경분에 대한 내용만 적용된다. Snapshot을 이용하여 복원 시 백업 시점, 즉 Snapshot 생성 시점의 기준 Data를 가지고 새로운 RDS 인스턴스로 생성되는 방식이다.
Autobackup 또한 지원하며 사용자가 지정한 Backup Window에 자동으로 백업이 수행된다.
대상 RDS가 Multi-AZ 구성이라면 Standby DB에서 백업이 진행되기 때문에 백업으로 인한 영향을 최소화시킬 수 있다.(SQL Server 제외)
또한 생성된 Snapshot은 다른 Region 혹은 AWS Account 간에도 공유가 가능하다.
4.1 Autobackup
RDS에서 Snapshot은 사용자가 Manaul (수동) / Auto (자동) 설정이 가능하며 1일부터 최대 35일까지 Autobackup 보관주기를 설정할 수 있다.
RDS의 Autobackup은 단순히 자동백업을 활성화하는 것에서 그치는 것이 아닌 백업 전략과도 연관되며 활성화 시에 DB 내부 설정이 바뀔 수 있다.
(Oracle로 예시를 들자면 Autobackup 활성화 시 Archive mode가 On으로 설정된다.)
또한 AWS 내부 S3에 Transaction Log를 5분 주기로 따로 백업을 진행하기 때문에 설정한 Autobackup 보관주기를 바탕으로 시/분/초 단위로 5분 전부터, 최대 보관주기까지 PITR(Point-In-Time-Recovery) Snapshot 시점복구가 가능하다.
예를 들어 Autobackup 기능을 활성화 하여 보관주기를 7일로 설정한다면, RPO(Recovery Point Objective)의 허용범위는 현재 시간 기준 5분전 ~ 7일전까지 시/분/초 단위의 인스턴스 레벨의 복구가 가능하다.
5. 확장성
데이터베이스는 기본적으로 OS위에서 동작하는 Software이며 RDS도 그 예외는 아니다.
RDS는 내부적으로 우리가 직접적인 접근은 불가능하지만 AWS EC2(Computing)와 EBS(Storage)로 구성되어 있다.
따라서 Instance Class(Computing)를 통해 자유롭게 Scale Up/Down이 가능하고 스토리지는 Autoscaling 기능도 지원하며 유연하게 확장 가능하다.
EC2와 마찬가지로 다양한 인스턴스 패밀리와 타입을 지원하고 있으며 스토리지의 경우 서비스의 워크로드 별로 다양한 유형을 지원하고 있다.
RDS Intance Class
- 범용 (db.m)
- 메모리 최적화 (db.r)
- 컴퓨팅 최적화 (db.t)
RDS Storage Class
- 범용 SSD (gp3)
- Provisioned IOPS (io2)
- Magnetic (권장 x)
참고로 RDS 스펙을 변경하는 Scale Up/Down의 경우 운영 중에는 DB Downtime이 발생하며 DB 엔진 및 버전별로 지원되는 타입이 제한될 수 있다. 스토리지의 경우 EBS의 특성상 증설은 가능하지만 반대로 축소는 불가능하다.
6. 보안
기본적으로 AWS에서 사용되는 네트워크 보안 모두 RDS에 적용 가능하다. (VPC, Private Subnet, Security Group..)
또한 IAM 기반의 리소스에 대한 권한 제어도 가능하기 때문에 기본적인 AWS 네트워크 보안 및 권한 제어가 가능하다.
Storage의 경우 AWS Key Magement Service인 KMS 키를 기본적으로 사용하며 Oracle과 SQL Server의 경우 On-Premise에서 사용되던 TDE 또한 적용이 가능하기에 Storage 레벨의 보안 또한 지원하고 있다.
추가로 RDS 설정에 따라 전송 중인 데이터에 대한 SSL/TLS 보안 또한 사용 가능하며 DB 접근제어 시스템 또한 그대로 사용 가능하다.
끝맺음.
본문에서도 언급을 했지만 On-Premise 환경에서 Cloud 환경으로 Migration 했다고 하더라도, DBA를 포함하여 기존에 존재했던 시스템 담당자들의 역할이 없어지는 것은 아니다. AWS Cloud 환경에 대해 잘 이해하고 고객의 Needs와 환경에 맞춰 네트워크 등 전반적인 설계/구성할 수 있는 SA(Solutions Architect)가 필요하고, 전반적인 Cloud DB (RDS / Aurora)에 대해 관리할 수 있는 DBA도 필요하다.
(SA분들은 존경한다. 짱짱맨)
RDS를 직접 운영해 보면서 느낀 점은 본문에서 설명했다시피 Cloud 형태로 넘어오면서 장점도 많이 있지만 분명히 단점과 리스크도 존재한다.
OS에 대한 접근이 제한되다 보니 이에 따른 제한사항이 많아지고 매년 버전에 대한 EOS/EOL이 공지되기 때문에 업그레이드 계획에 대한 압박이 있다. 또한 전반적인 AWS Network 및 EC2, S3 등 AWS지식을 필요로 하며 모든 것은 비용과 직결되기 때문에 모르고 사용한다면 비용폭탄을 맞을 수도 있다.
다음에 기회가 된다면 AWS의 전반적인 네트워크에 대해서 공부하며 기록해보고 싶다. On-Premise에서도 마찬가지겠지만 Database만 잘 아는 것과 OS, Netwoerk, 보안 등 여러 영역에 대해 잘아는 것은 정말 큰 차이가 있다.
오늘은 RDS의 주요 특징과 기능들에 대해 나름 간략하게 정리해 봤다. 이밖에도 다양한 RDS 기능 및 특징들이 있으며 매년 새로운 기능들이 출시되고 있다.
다음에는 RDS 생성부터 시작하여 각 옵션들에 대해 살펴볼 거고, 접속은 어떻게 해야 되는지 포스팅할 생각이다.